Spam Classifier
Introduction
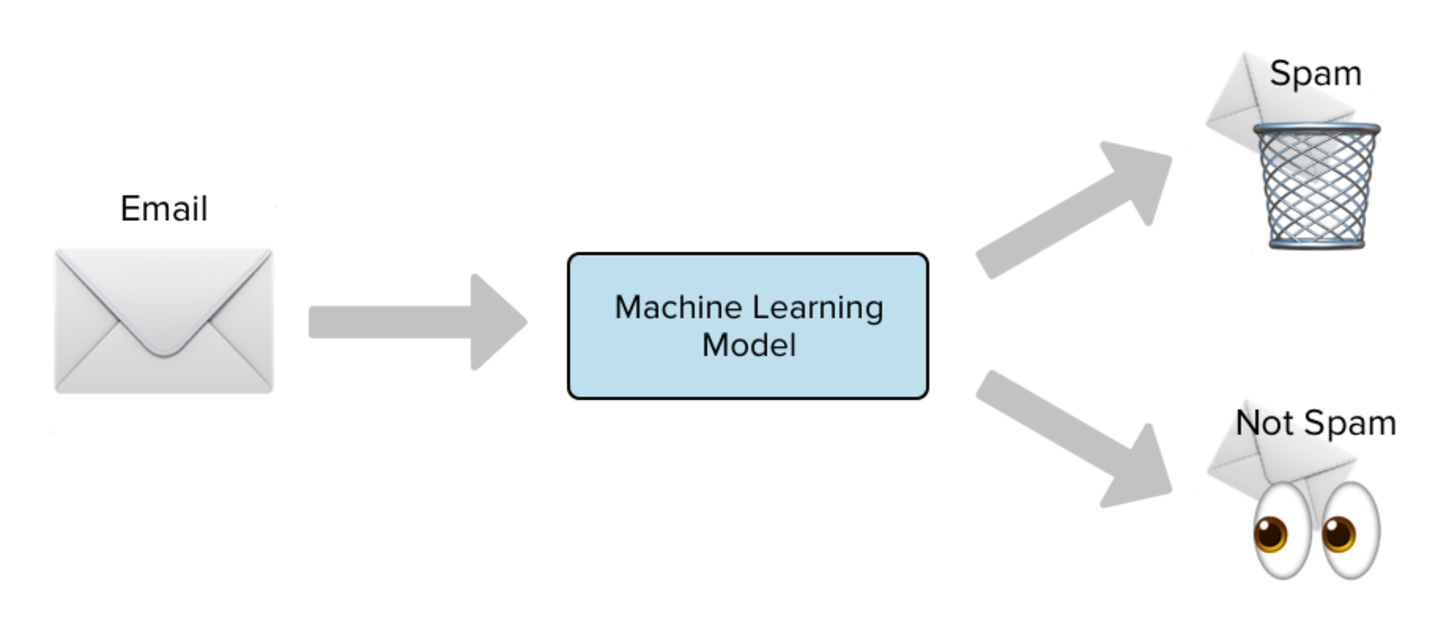
Today we are going to explore Naives Bayesian algorithm by looking at a concrete example that I’have implemented for my school project. The goal of this project is to develop a model that can accurately classify incoming emails as either spam or non-spam (ham).
Naives Bayes Classifier
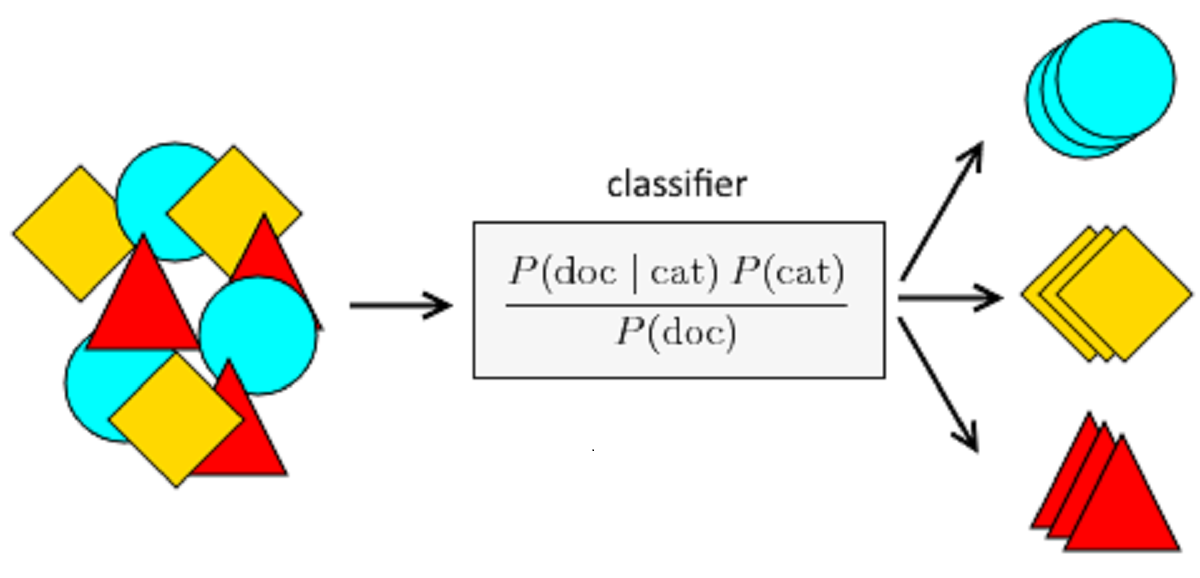
The Naive Bayes classifier is a simple yet powerful machine learning algorithm commonly used for text classification tasks, such as spam detection, sentiment analysis, and document categorization. In our case of spam classification, the Naive Bayes classifier proves to be a suitable choice. The algorithm’s simplicity and effectiveness make it well-suited for dealing with textual data, such as emails.
Mathematical model
To delve deeper into the Naive Bayes classifier, let’s discuss its mathematical model. The classifier uses Bayes’ theorem to calculate the probability of a particular class given the observed features. The mathematical formulation of the Naive Bayes classifier can be represented as follows:
Given a feature vector $x = (x₁, x₂, …, xₙ)$, where $xᵢ$ represents the i-th feature, and a set of classes $C = {c₁, c₂, …, cₖ}$, the Naive Bayes classifier calculates the posterior probability $P(cᵢ \mid x)$ for each class $cᵢ$, where $P(cᵢ \mid x)$ represents the posterior probability of class $cᵢ$ given the observed features $x$. The class with the highest posterior probability is assigned as the predicted class for the input feature vector.
Bayes’ theorem states that the posterior probability $P(cᵢ \mid x)$ can be calculated using the following formula:
$P(c_i \mid x) = \frac{P(x \mid c_i) \cdot P(c_i)}{P(x)}$
- $P(cᵢ)$ represents the prior probability of class $cᵢ$, which is the probability of encountering class $cᵢ$ in the training set.
- $P(x \mid cᵢ)$ represents the likelihood probability, which is the probability of observing the feature vector $x$ given class $cᵢ$.
- $P(x)$ is the evidence probability, which is the probability of observing the feature vector $x$ irrespective of the class.
Example
Let’s say we have the following dataset :
1
2
3
4
5
6
7
8
| Email | Free | Limited | Class |
|-------|-------------|-------------|-------|
| 1 | Present | Not Present | Spam |
| 2 | Not Present | Present | Ham |
| 3 | Not Present | Not Present | Ham |
| 4 | Present | Not Present | Spam |
| 5 | Not Present | Present | Spam |
| 6 | Present | Present | Ham |
For example, we have the following probabilities estimated from the training data:
- $P(Spam)=0.5$
- $P(Ham)=0.5$
- $P(x_{1}=Free∣Spam)=\frac{2}{3}$
- $P(x_{1}=Free∣Ham)=\frac{1}{3}$
- $P(x_{2}=Limited∣Spam)=\frac{1}{3}$
- $P(x_{2}=Limited∣Ham)=\frac{2}{3}$
- $P(x_{1}=Free)=0.5$
- $P(x_{2}=Limited)=0.5$
We can now calculate the probability of a file being classified as a spam $c_{0}$ knowing that it contains $x_{1}$ :
$P(c_{0} \mid x_{1}) = \frac{P(x_{1} \mid c_{0}) \cdot P(c_{0})} {P(x_{1})} = \frac{P(Free \mid Spam) \cdot P(Spam)}{P(Free)}=\frac{0.6 \cdot 0.5}{0.5}=\frac{2}{3}$
$P(c_{1} \mid x_{1}) = \frac{P(x_{1} \mid c_{1}) \cdot P(c_{1})}{P(x_{1})}=\frac{P(Free \mid Ham) \cdot P(Ham)}{P(Free)}=\frac{0.3 \cdot 0.5}{0.5}=\frac{1}{3}$
Spamicity of a file
Okay we seen how to calculate the spamicity of a word but what about a file that contains a dozen of words ? In order to make this possible we need to make the following naives assumption “each words in the file represents indepant events”. We can then deduce a formula for the spamicity of a file :
$ p = \frac{p_{1}\cdot p_{2} \cdot…\cdot p_{n}}{p_{1}\cdot p_{2} \cdot … p_{n} + (1-p_{1})\cdot(1-p_{2})\cdot … \cdot (1-p_{n})}$
where :
- $p$ is the probability that the file is a spam.
- $p_{1}$ is the probability $P(x_{1}\mid Spam)$, probability of file being spam knowing that it contains word $x_{1}$.
- $p_{2}$ is the probability $P(x_{2}\mid Spam)$, probability of file being spam knowing that it contains word $x_{2}$.
- etc.
- $p_{n}$ is the probability $P(x_{n}\mid Spam)$, probability of file being spam knowing that it contains word $x_{n}$.
Why it works ?
The Naive Bayes classifier assumes that the features are conditionally independent given the class label. This assumption simplifies the calculation of probabilities, as it allows us to model the likelihood probability of each feature independently. Although this assumption may not always hold true in real-world scenarios, Naive Bayes has shown to work well in practice, especially for text classification tasks.
Suppose we have a dataset of emails labeled as either spam or non-spam, and we want to classify new emails based on their content. We focus on two features: the presence of the word “discount” and the presence of the word “urgent”.
The independence assumption in Naive Bayes implies that the occurrence of the word “discount” in an email is independent of the occurrence of the word “urgent” given the class label (spam or non-spam). In other words, the presence of “discount” does not provide any information about the presence of “urgent” within the same email.
Dataset
The first step in any machine learning project is to gather and prepare the data. For this project, we will use a pre-existing dataset of labeled emails. The dataset will consist of a collection of emails, where each email is labeled as spam or non-spam. The dataset will be split into training and testing sets to evaluate the performance of the classifier.
In our case we have two folders HAMS and SPAMS.:
1
2
3
4
5
6
7
8
9
10
├── SPAMS
│ └── 1_spam.txt
│ └── 2_spam.txt
│ └── 3_spam.txt
│ └── ...
├── HAMS
│ └── 1_ham.txt
│ └── 2_ham.txt
│ └── 3_ham.txt
│ └── ...
Let’s see how many files are in each folders :
1
2
$ ls SPAMS | wc -l : 1378
$ ls HAMS | wc -l : 2949
Let’s seek further by couting the total number of words in each files :
1
2
$ cat * | wc -w : 601540 in SPAMS
$ cat * | wc -w : 857300 in HAMS
The dataset is not unbalanced even if we have a little more hams than spams.
Content of spam file :
1
2
3
4
5
6
7
8
9
One of a kind Money maker! Try it for free!From nobody Sun Jan 03 19:33:39 2016
Content-Type: text/html;
charset="iso-8859-1"
Content-Transfer-Encoding: 7bit
<body lang=EN-US>
<div class=Section1>
[...]
Content of ham file :
1
2
3
4
5
6
7
8
9
10
11
Re: (no subject)I've picked up these patches and will submit to CVS eventually.
If there are bugs worth fixing, please let me know about the fixes
for them.
>>>Mark Scarborough said:
>
> tg@sema.se said:
> > mscar <mscar-list-exmh@cactus.org> said:
> > > My biggest problem with it is that it will _always_ render
the HTML
[...]
We can see that our data does not contains only words we will treat that trough preprocessing.
Preprocessing
Before feeding the data into the machine learning model, we need to preprocess it to extract relevant features. Some common preprocessing steps for text data include:
- Tokenization: Splitting the text into individual words or tokens.
- Lowercasing: Converting all text to lowercase to avoid duplication based on case.
- Removing stop words: Eliminating common words that do not provide much information.
- Lemmatization: Reducing words to their base or root form.
Since the project is focused on implementing the classifier we will not see in details how to implement Lemmatization.
Example
We will use this example to test our preprocessing methods :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<p class=MsoBodyText style='text-align:justify'><b>CONSANTLY</b> being
bombarded by so-called �FREE� money-making systems that teases you with limited
information, and when it�s all said and done, blind-sides you by demanding your
money/credit card information upfront in some slick way,<b> after-the-fact</b>!
Yes, I too was as skeptical about such offers and the Internet in general with
all its hype, as you probably are. Fortunate for me, my main business
slowed-down (<i>I have been self-employed all my life</i>), so I looked for
something to fit my lifestyle and some other way to assist me in paying my
bills, without working myself to death or loosing more money; then, this
proposal to try something new without any upfront investment (<i>great! because
I had none</i>) interested me to click on the link provided. And I don�t regret
at all that I did! I am very happy, and happy enough to recommend it to you as
a system that is true to its word. I mean absolutely no upfront money. You join
only if (<i>when</i>) you make money. You also get to track the results of your
time and efforts instantly and updated daily! I especially liked this idea of
personal control with real-time, staying informed statistics.</p>
Regex
We see that in the above example there is a lot of unecessary junks for our model, remember we only want to keep words that are relevant of the message context. A good way to remove unwanted tags is by using regular expressions :
1
pattern = r'<[^<]+?>|\d+|[^\w\s]|[^\x00-\x7F]+|http\S+'
<[^<]+?>: Matches HTML tags enclosed within angle brackets, such as
. This pattern looks for a < character, followed by one or more characters that are not <, and ends with a > character. It helps in removing HTML tags from the text \d+: Matches one or more consecutive digits. This pattern is used to identify and remove numeric digits from the text.
[^\w\s]: Matches any character that is not a word character (alphabet, digit, or underscore) or whitespace. This pattern helps in identifying and removing special characters that are not part of words or spaces.
[^\x00-\x7F]+: Matches one or more consecutive characters that are not within the ASCII range (characters with values outside the range of 0-127). This pattern is used to identify and remove non-ASCII characters, such as special symbols or foreign language characters
http\S+: Matches URLs starting with “http://” or “https://” followed by one or more non-whitespace characters. This pattern helps in identifying and removing URLs from the text.
Let’s run the code on the above example :
1
2
3
4
import re
email = """<p class=MsoBodyText style='text-align:justify'><b>CONSANTLY</b> being bombarded by so-called ..."""
pattern = r'<[^<]+?>|\d+|[^\w\s]|[^\x00-\x7F]+|http\S+'
email_without_pattern = re.sub(pattern, '', email)
Which gives us :
1
2
3
4
5
6
7
8
9
10
11
12
13
CONSANTLY being bombarded by socalled FREE moneymaking systems that teases you with limited information and when its all said and done blindsides you by demanding your moneycredit card information upfront in some slick way afterthefact
Yes I too was as skeptical about such offers and the Internet in general with
all its hype as you probably are Fortunate for me my main business
sloweddown I have been selfemployed all my life so I looked for
something to fit my lifestyle and some other way to assist me in paying my
bills without working myself to death or loosing more money then this
proposal to try something new without any upfront investment great because
I had none interested me to click on the link provided And I dont regret
at all that I did I am very happy and happy enough to recommend it to you as
a system that is true to its word I mean absolutely no upfront money You join
only if when you make money You also get to track the results of your
time and efforts instantly and updated daily I especially liked this idea of
personal control with realtime staying informed statistics
That’s perfect, now we can tokenize and lower the text :
1
email_tokenized = email_without_pattern.lower().split()
Next we remove stop words :
1
2
3
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
email_without_stop_words = [word for word in email_tokenized if word not in stop_words]
We get this bueatiful list :
1
['consantly','bombarded','socalled','free','moneymaking','systems',...]
Now here comes the last part lemmatization :
1
2
3
4
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
email_lemmatized = [lemmatizer.lemmatize(word) for word in email_without_stop_words]
Model Training
With the preprocessed data, we can now train a machine learning model.
Splitting training and testing sets
Before training the machine learning model, it is important to split the preprocessed data into separate training and testing sets. The purpose of this step is to evaluate the performance of the trained model on unseen data. Typically, a common split is to allocate around 80% of the data for training and the remaining 20% for testing.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
SPAM_FOLDER='HAMS'
HAM_FOLDER='SPAMS'
training_percent = 0.8
files = os.listdir(SPAM_FOLDER)
# Take 99% of the files for training randomly
training_files_spams = np.random.choice(files, int(len(files) * training_percent), replace=False)
# Take the rest for testing
testing_files_spams = [SPAM_FOLDER + '/' + file for file in files if file not in training_files_spams]
files = os.listdir(HAM_FOLDER)
# Take 90% of the files for training randomly
training_files_hams = np.random.choice(files, int(len(files) * training_percent), replace=False)
# Take the rest for testing
testing_files_hams = [HAM_FOLDER + '/' + file for file in files if file not in training_files_hams]
Probabilities dictionnary
We need to estimate the probabilities of different features given each class. We can create a probabilities dictionary to store these probabilities.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# Dictionary : word | count in SPAM | count in HAM | P(word|SPAM) | P(word|HAM) | P(SPAM|word)
word_count_dict = {}
for filename in training_files_spams:
with open(os.path.join(SPAM_FOLDER, filename), 'r') as f:
file_words = f.read()
# Remove pattern
file_words = re.sub(pattern, '', file_words)
# Tokenize
file_words = file_words.lower().split()
for word in file_words:
if word not in stop_words:
# Lemmatize the word
word = lemmatizer.lemmatize(word)
if word not in word_count_dict:
word_count_dict[word] = {'SPAM': 1, 'HAM': 0}
else:
word_count_dict[word]['SPAM'] += 1
for filename in training_files_hams:
with open(os.path.join(HAM_FOLDER, filename), 'r') as f:
file_words = f.read()
# Remove pattern
file_words = re.sub(pattern, '', file_words)
# Tokenize
file_words = file_words.lower().split()
for word in file_words:
if word not in stop_words:
# Lemmatize the word
word = lemmatizer.lemmatize(word)
if word not in word_count_dict:
word_count_dict[word] = {'SPAM': 0, 'HAM': 1}
else:
word_count_dict[word]['HAM'] += 1
# Calculate the probabilities
for word in word_count_dict:
word_count_dict[word]['P(word|SPAM)'] = word_count_dict[word]['SPAM'] / (word_count_dict[word]['SPAM'] + word_count_dict[word]['HAM'])
word_count_dict[word]['P(word|HAM)'] = word_count_dict[word]['HAM'] / (word_count_dict[word]['SPAM'] + word_count_dict[word]['HAM'])
word_count_dict[word]['P(SPAM|word)'] = word_count_dict[word]['P(word|SPAM)'] / (word_count_dict[word]['P(word|SPAM)'] + word_count_dict[word]['P(word|HAM)'])
# Limit for not having to calculate infinite value
if word_count_dict[word]['P(SPAM|word)'] == 0:
word_count_dict[word]['P(SPAM|word)'] = 0.01
elif word_count_dict[word]['P(SPAM|word)'] == 1:
word_count_dict[word]['P(SPAM|word)'] = 0.99
# Store the dictionary in a file
with open('word_count_dict.txt', 'w') as f:
# Write the header
f.write('word SPAM HAM P(word|SPAM) P(word|HAM) P(SPAM|word)\n')
for word in word_count_dict:
f.write(word + ' ' + str(word_count_dict[word]['SPAM']) + ' ' + str(word_count_dict[word]['HAM']) + ' ' + str(word_count_dict[word]['P(word|SPAM)']) + ' ' + str(word_count_dict[word]['P(word|HAM)']) + ' ' + str(word_count_dict[word]['P(SPAM|word)']) + '\n')
The following dictionnary is stored in a separate file, we will use it to calculate spacimicity of a given file with the propabilities stored.
1
2
3
4
5
6
7
8
9
10
word SPAM HAM P(word|SPAM) P(word|HAM) P(SPAM|word)
video 1336.0 0.0 1.0 0.0 0.99
provides 668.0 0.0 1.0 0.0 0.99
powerful 334.0 0.0 1.0 0.0 0.99
way 667.0 0.0 1.0 0.0 0.99
help 667.0 0.0 1.0 0.0 0.99
prove 334.0 0.0 1.0 0.0 0.99
point 334.0 0.0 1.0 0.0 0.99
click 1999.0 0.0 1.0 0.0 0.99
online 668.0 0.0 1.0 0.0 0.99
File spamicity
Probabilities
To calculate the spamicity of a file, we need to do the same previously seen preprocessing of the new file. After doing this we can then calculate the spaminess of our file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
word_count_dict = {}
with open('word_count_dict.txt', 'r') as f:
for line in f:
if not line.startswith('word'):
line = line.split()
word_count_dict[line[0]] = {'SPAM': float(line[1]), 'HAM': float(line[2]), 'P(word|SPAM)': float(line[3]), 'P(word|HAM)': float(line[4]), 'P(SPAM|word)': float(line[5])}
new_file_spamicities = {}
pattern = r'<[^<]+?>|\d+|[^\w\s]|[^\x00-\x7F]+|http\S+'
with open(os.path.join(filename), 'r', errors="ignore") as f:
file_words = f.read()
# Remove patterns
file_words = re.sub(pattern, '', file_words)
# Tokenize
file_words = file_words.lower().split()
for word in file_words:
if word not in stop_words:
# Lemmatize the word
word = lemmatizer.lemmatize(word)
if word in word_count_dict:
spamicity = word_count_dict[word]['P(SPAM|word)']
new_file_spamicities[word] = {'P(SPAM|word)': spamicity}
else:
new_file_spamicities[word] = {'P(SPAM|word)': 0.4}
After this we get the spamicity of each words in the file stored in a dictionnary similar to the first dictionnary that we used for training.
Deviation from mean spamicity
To calculate the spamicity of a file, we can utilize the probabilities obtained from the training data. Once we have preprocessed the new file and obtained the word spamicities, we can calculate the deviation of each word’s spamicity from the mean spamicity. This deviation will give us an indication of how spammy or hammy each word is relative to the mean spamicity of the file.
By considering only words that highly deviate from the mean spamicity, we can potentially capture words that are more indicative of spam or non-spam content. This approach helps in identifying words that have a stronger association with a particular class (spam or non-spam) and can improve the accuracy of the spamicity calculation.
When a word has a high deviation from the mean spamicity, it means that its occurrence in spam emails is significantly different from its occurrence in non-spam emails. By focusing on these deviating words, we can prioritize the features that contribute more to the classification task and potentially achieve better results.
We calculate the mean spamicity of the file :
1
2
# calculate mean of spamicities
mean_spamicity = sum(new_file_spamicities[word]['P(SPAM|word)'] for word in new_file_spamicities) / len(new_file_spamicities)
Then let’s say that we only want a subset of $n$ words with high deviation from the mean, so we have $n/2$ word with lowest spamicity and $n/2$ with highest :
1
2
3
4
5
6
7
8
9
10
11
12
13
word_with_lowest_spamicity = [word for word in new_file_spamicities if new_file_spamicities[word]['P(SPAM|word)'] < mean_spamicity]
word_with_highest_spamicity = [word for word in new_file_spamicities if new_file_spamicities[word]['P(SPAM|word)'] > mean_spamicity]
# order words with highest spamicity above mean
word_with_highest_spamicity = sorted(word_with_highest_spamicity, key=lambda x: new_file_spamicities[x]['P(SPAM|word)'], reverse=True)
# order words with lowest spamicity below mean
word_with_lowest_spamicity = sorted(word_with_lowest_spamicity, key=lambda x: new_file_spamicities[x]['P(SPAM|word)'])
# Take the n/2 words with highest spamicity above mean and the n/2 words with lowest spamicity below mean
word_with_lowest_spamicity = word_with_lowest_spamicity[:int(n/2)]
word_with_highest_spamicity = word_with_highest_spamicity[:int(n/2)]
words_with_high_deviation = word_with_highest_spamicity + word_with_lowest_spamicity
Calculating spamicity
Now everythings is setup for getting the spaminess of the file, we just needs to make the calculation from the given formula :
1
2
3
4
5
6
7
8
9
10
11
12
numerator = 1
denominator = 1
l = 1
for word in words_with_high_deviation:
spamicity = new_file_spamicities[word]['P(SPAM|word)']
numerator *= spamicity
denominator *= spamicity
l *= (1 - spamicity)
denominator += l
spamicity = numerator / denominator
If we plot it :
